


Shop by Category











Special Promotion




Special Promotion


Special Promotion


For The Immediate delivery contact the sales team. Usually, Ship in 2-3 days, images are for illustration purposes only.
Call for Price
PN: 41901
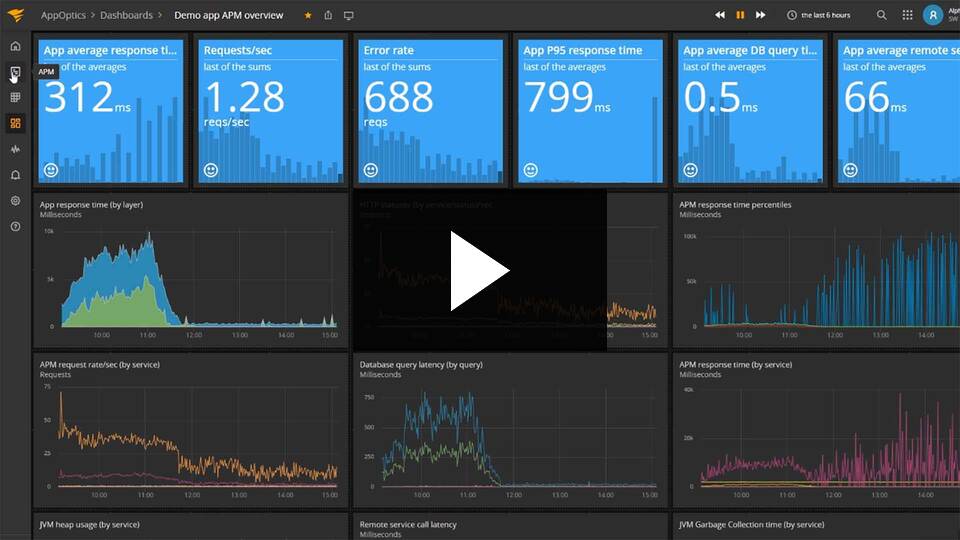
SolarWinds AppOptics is a SaaS-based application performance monitoring (APM) solution. It’s a convergence of application performance monitoring, infrastructure monitoring, and custom metrics into a single, simple tool that delivers a deeper and wider understanding of system availability and performance.
A trace is the path of a single request through an application. AppOptics gathers traces on a continuous basis and mines them for data, then makes them available in the UI filterable based on a number of criteria.
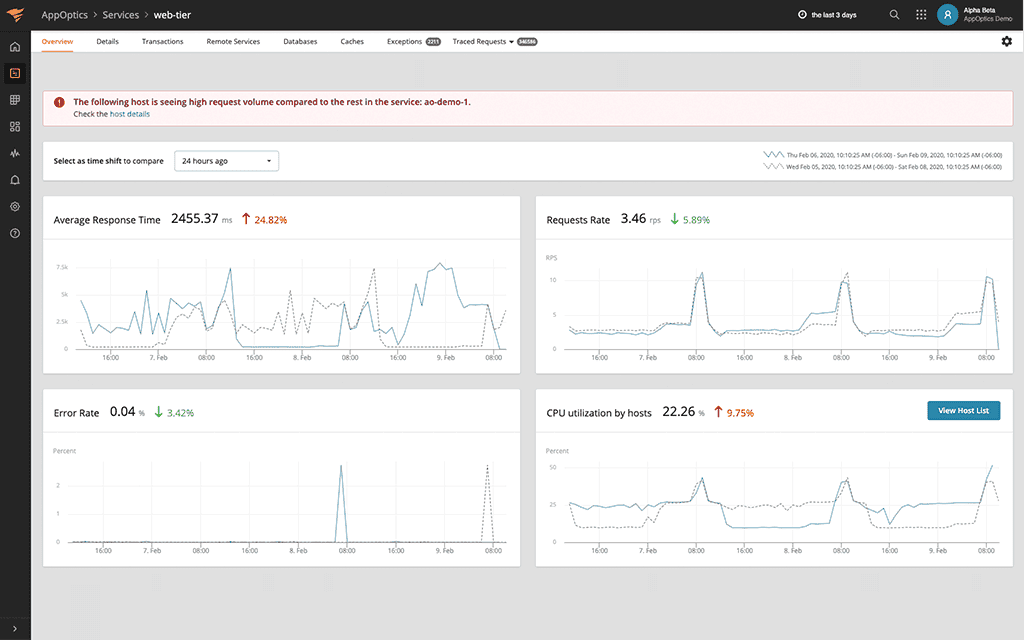
At a high level, traces are grouped by service (though a single trace can span multiple services), and you can find them under each service’s Overview page.
The heat map chart shows a histogram of the request latency. The y-axis represents the request latency, and the color intensity of the chart represents the number of requests. The darker the color, the more requests. This chart type makes it easy to identify outliers. You can further adjust the chart to only show requests below certain percentiles and limit the number of rows displayed. To learn about specific traces you can click and drag your mouse around a specific request or group of requests on the chart. This will filter the list of traces beneath the chart to only show the ones in the area you selected.

Filtering: By using the Filter By feature you have the ability to filter by any of the suggested tags, e.g. drill down into a specific transaction.
Scope: By default, we show the Traced Requests–traces of requests to the service in question. If you hover over Traced Requests you will see a dropdown menu that allows you to switch to database queries, remote service calls, or cache calls.

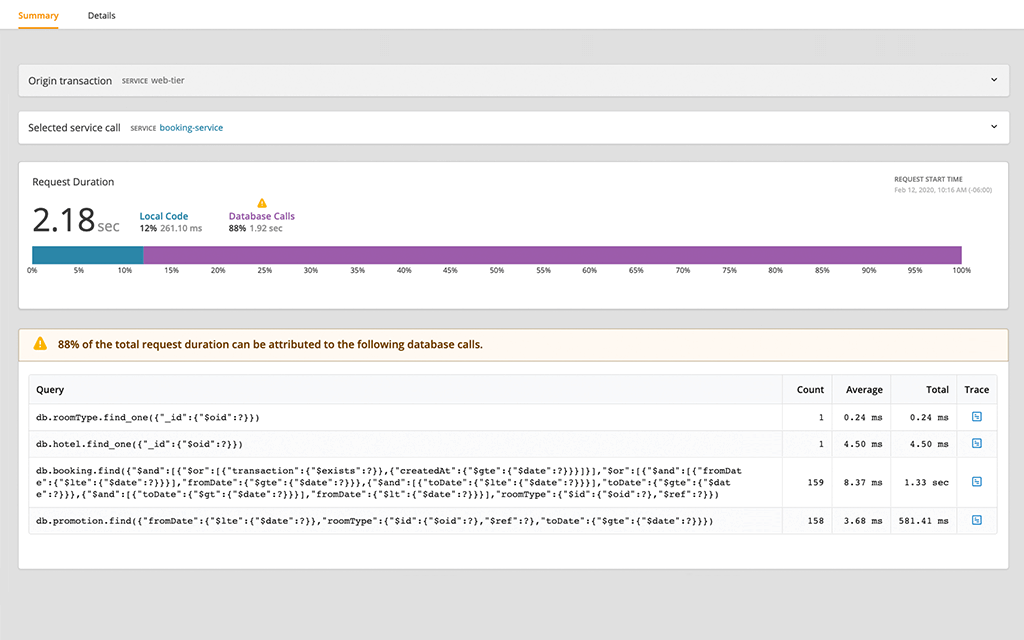
When you first navigate to a particular trace, you will be taken to the Summary tab. This is a good place to start if you want to just get a quick idea of where most of the time is being spent for a request.
The trace summary automatically evaluates a transaction and highlights where the service is spending most of its time. For example, if a particular transaction is mostly waiting on queries, that will be highlighted and you’ll get a summary of the specific queries. If the transaction is slowed down by a downstream service or external API calls, that’s covered too. If you’re instrumenting custom code in your application, the new summary page paired with live code profiling will even tell you which function was slow.

A single trace could be as simple as a single span on a web server hosting static content, or as complex as the path through a load balancer into one of many app servers, through to an API call, and back again. For those more complicated requests, if you wish to take a deeper dive into analyzing your application performance, waterfall-type views are available in the Details tab.

As previously noted, traces can span across multiple services. You can view the details for this trace within a specific service by using the Trace Breakdown by dropdown. In this example, the only service this trace interacts with is api.

Clicking on a span in the chart opens up a detail window on the right. In the example below, the sequel span was selected, which is a Ruby library being used by this application to query a database. The detail window shows information from the database name right down to the query that was executed.

The tables below the visualization are also interactive: clicking a row in the table will pull up details about the relevant span(s) in the right-hand panel.
If any errors occur during the duration of the trace, they will be displayed in the All Errors table. Opening the detail window for a span shows high-level information about the errors, including a link to the full backtraces. In the example below, the insertworker span is a Python process that threw a ConnectionError exception.

Your business runs on applications, and when they go down or run slowly, it can impact the business in lost productivity, customers, or revenue. To add to the complexity, your IT environment is changing, and workloads can be spread across data centers and cloud resources. You need to monitor the availability and performance of applications and infrastructure, regardless of where they are, so you can identify potential issues early and address them before they impact users.
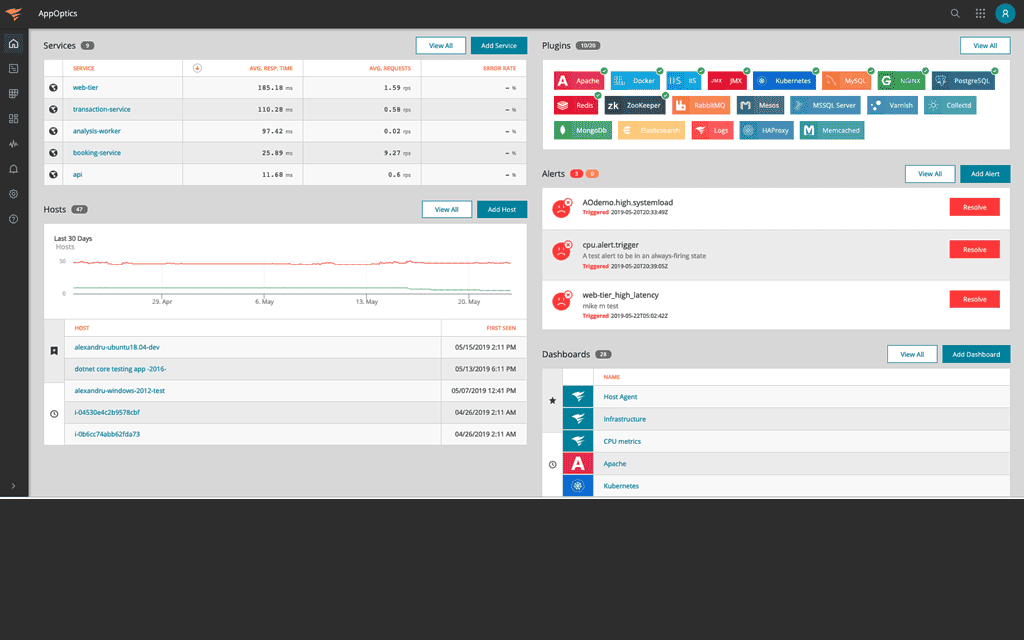
Complete visibility into the health and performance of your applications and their supporting infrastructure.
Create performance metrics to automate monitoring of business-critical services and applications.
Minimize downtime with early warning notifications. If systems fail, help ensure you can recover quickly.
Support the ebbs and flows of your business. Use a cloud-scale APM tool designed for today’s dynamic IT environment.
The service map is meant to provide context for how a service or dependency translates to end-user performance. With the application service map, you can move into a particular service to view more detailed performance metrics (root cause of service degradation, transaction traces, exceptions, performance over time, etc.).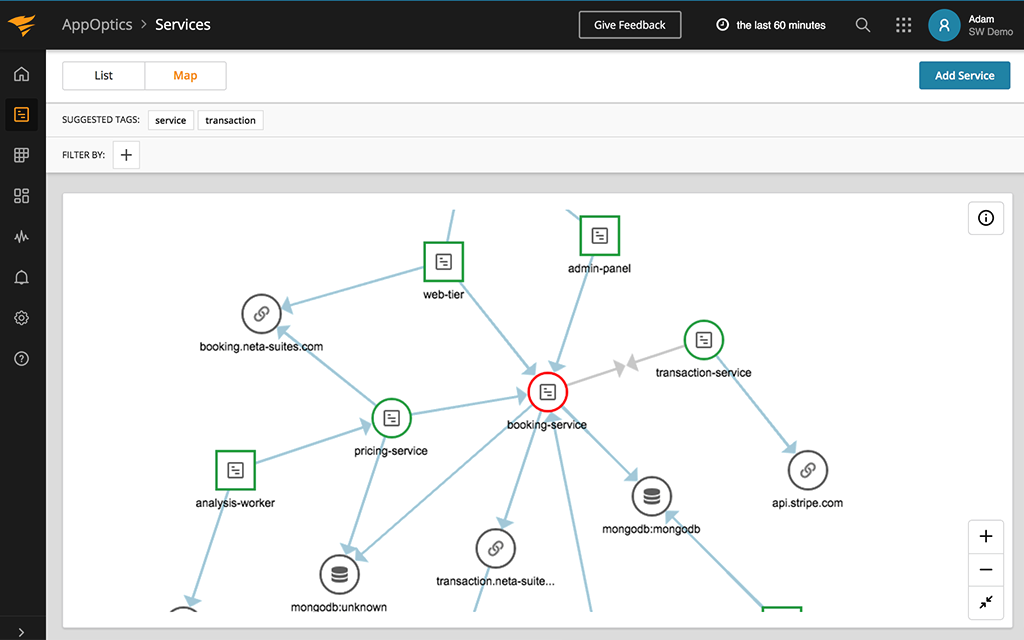
AppOptics trace- and service-level root cause simplify pinpointing application performance issues. These simplified views work for legacy monolithic applications just as well as they work for modern apps running in Kubernetes. Remove the guesswork from your incident response and have your teams focus on working together to solve the problem.
AppOptics performance monitoring goes deep and wide, including applications, transactions, services, servers, hosts, containers, and serverless. It’s powerful made simple with auto-instrumentation, a one-click connection from hosts and transactions to their associated logs, and simplified root cause summaries, making APM valuable in just about anyone’s hands.
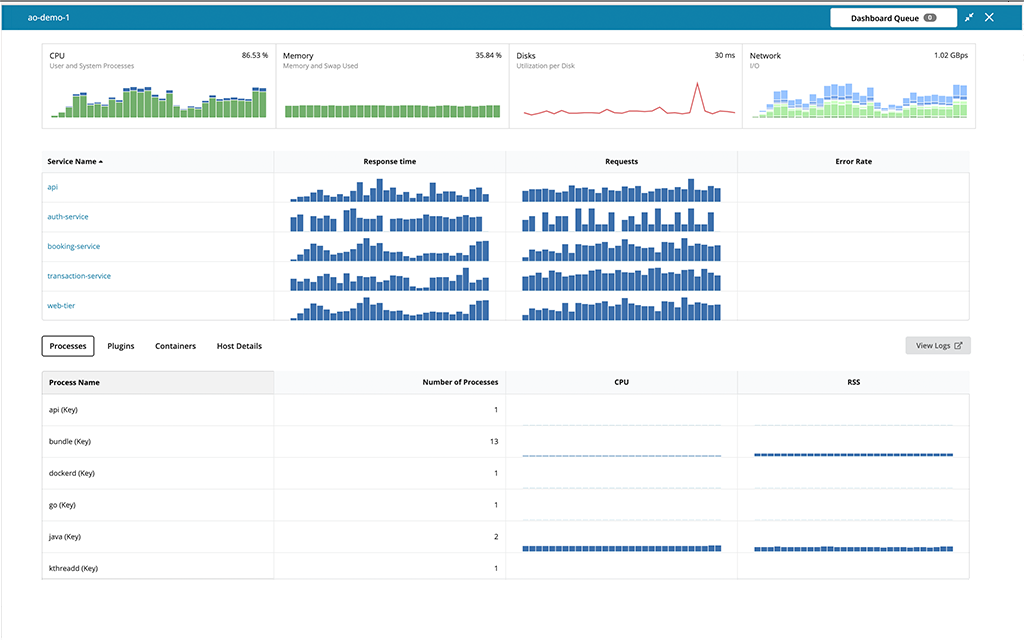
Get a bird’s-eye view across all your servers, hosts, containers, and serverless environments. Cross-reference application and infrastructure metrics side by side in the same dashboard.
Infrastructure monitoring for your legacy and new IT implementations with simple-to-click drilldowns into resource utilization and performance by services, containers, and processes.
Monitor over 30 AWS services with broad application language support (.Net, Java, PHP, Python, Scala, Node.js, Go, and Ruby).
Monitor Azure services including Load Balancer, Cosmos DB, SQL Database, Redis, and Azure App Services with broad application language support (Java, PHP, Python, Scala, Node.js, Go, and Ruby).
Avoid downtime with color-coded heatmaps that provide visualizations of all your hosts, and containers with comprehensive alerting on key performance metrics across the stack.
Measure what matters with AppOptics. It’s an APM tool offering the ability to perform full-stack monitoring of your systems, including key business metrics associated with those applications.
Achieve complete observability and accelerate troubleshooting by integrating synthetic monitoring and real-user monitoring powered by SolarWinds® Pingdom®.
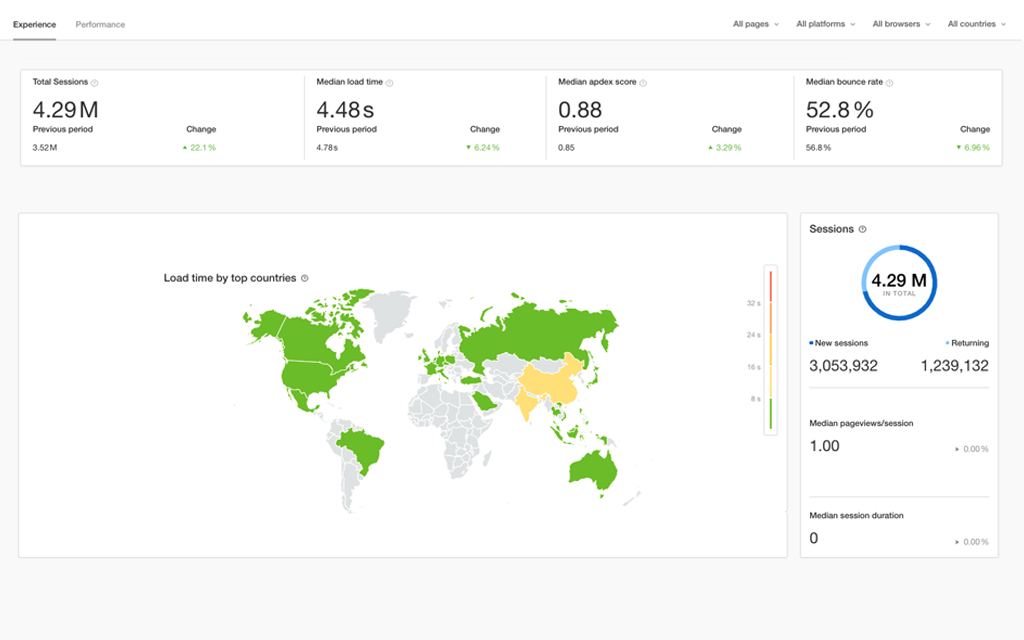
Achieve complete observability by integrating your metric, trace, and log data into a single integrated APM experience. Accelerate troubleshooting and identification of the root cause of performance issues.
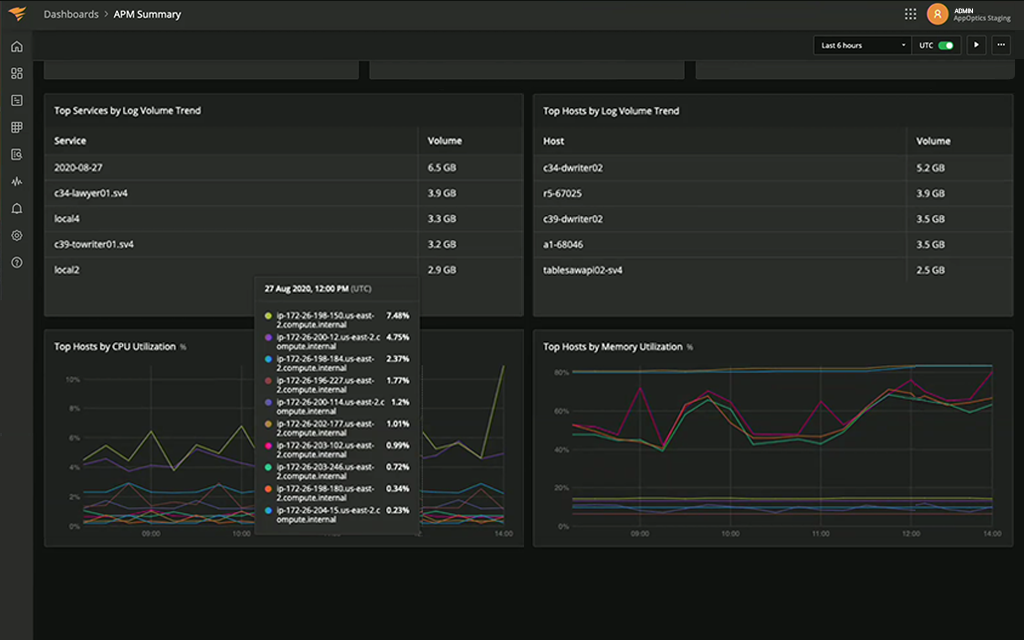
Single pane of glass visualization of thresholds that have been exceeded, paired with comprehensive alerting through major notification services like Slack, PagerDuty, Opsgenie, email, webhooks, and more.

Monitoring infrastructure and application metrics side by side, reduces the time it takes to identify what part of the stack is failing, so you can quickly get to root cause.
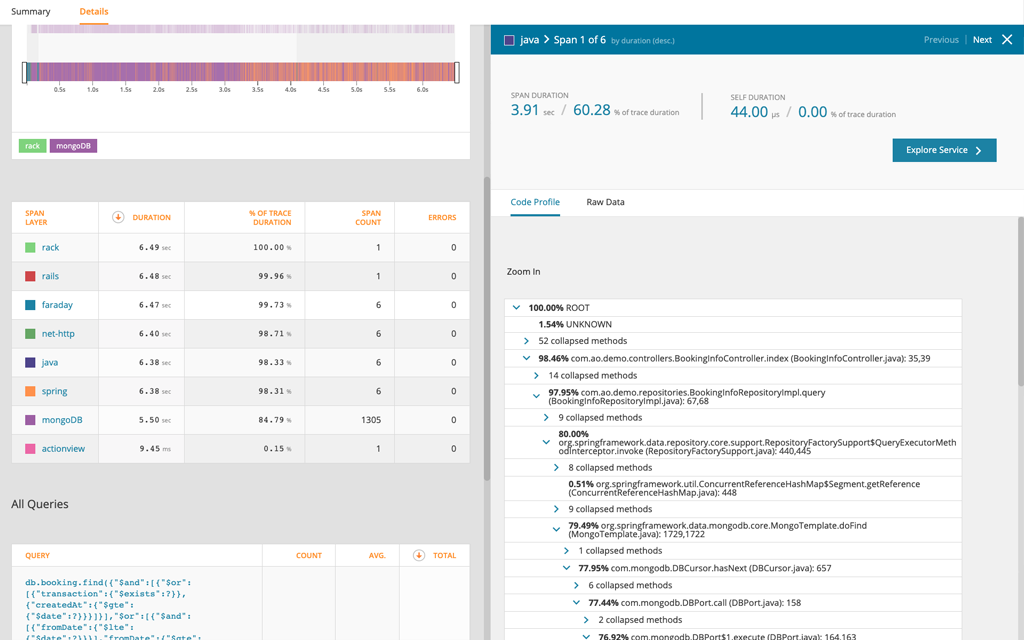
Code profiling combined with distributed trace enables you to go beyond the poor-performing service and identify the line of code causing the poor performance.
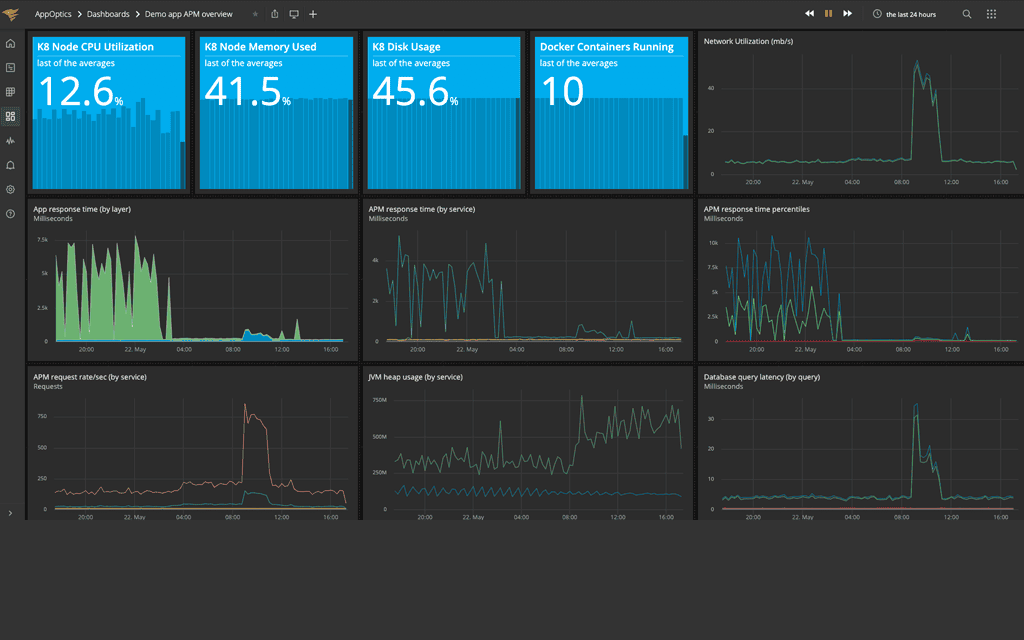
Incorporate custom metrics to combine business metrics side by side with system metrics. See and measure the impact infrastructure and application performance has on your business performance.
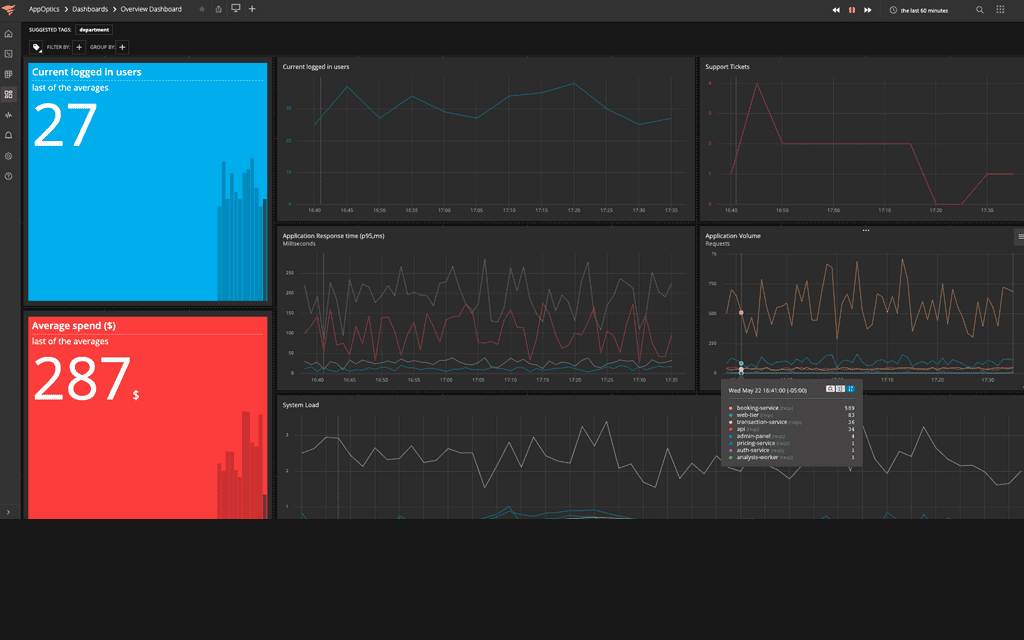
Leverage out-of-the-box dashboards and analytics to maximize performance while ensuring you don’t overspend or under-utilize precious on-premises and cloud resources.











Reviews
There are no reviews yet.